Data-Centric AI 관점으로 재해석하는 자연언어처리 기반 History of AI
2023/06/16 | 5 mins
-
박찬준 (AI Research Engineer)
-
Data-centric AI가 궁금하신 분
자연언어처리(NLP)에 대해 알고 싶으신 분
인공지능, 자연어처리의 역사가 궁금하신 분 -
인공지능 70년 역사의 주요 분야 중 하나인 자연언어처리(NLP)를 Data-Centric AI 관점으로 재해석해 보면 어떤 인사이트를 얻을 수 있을까요?
규칙 기반, 통계 기반, 기계학습 기반, 딥러닝 기반을 거쳐 Large Language Model(LLM)의 시대에 이르기까지 AI의 흐름을 되짚어봅니다.
-
✔️ 자연언어처리(NLP)란?
✔️ 모두를 위한 “언어모델의 역사”
✔️ Word2Vec
✔️ ELMo
✔️ Transformer기반 언어모델의 등장
✔️ LLM 시대의 필수 요소
✔️ 데이터 관점에서 사람에 대한 정의
✔️ 규칙기반 자연언어처리: “전문가”의 시대
✔️ 통계기반 자연언어처리~기계학습 및 딥러닝의 시대: “대중”의 시대
✔️ Pretrain-Finetuning의 시대: “대중” + “전문가”의 시대
✔️ 뉴럴심볼릭의 시대: “전문가”의 시대
✔️ Large Language Model의 시대 Part 01 - “대중”의 “무의식적” 데이터 생성의 시대
✔️ Large Language Model의 시대 Part 02 - “대중”의 “의식적” 데이터 생성의 시대
✔️ 마무리하며
💡 AlphaGo, ChatGPT, HyperClova 등의 등장으로, 이제 일반인들도 인공지능에 익숙한 시대로 돌입하였습니다. 인공지능이 21세기 들어 처음 등장한 학문 같이 느껴지지만, 사실 인공지능이라는 용어는 무려 1956년 미국 다트머스 대학(Dartmouth College)에서 열린 워크숍에서 존 매카시(John McCarthy) 교수님을 통해 탄생하게 되었습니다. 즉 인공지능이라는 학문이 시작된지는 무려 70년 가까이 되어간다는 것이죠. 본 기고글에서는 인공지능 70년의 역사 중, 특히 자연언어처리의 역사를 Data-Centric AI 관점으로 재해석해보려 합니다. 규칙 기반, 통계 기반, 기계학습 기반, 딥러닝 기반을 거쳐 Large Language Model의 시대까지의 흐름을 데이터 관점으로 살펴봅니다.
자연언어처리(NLP)란?
자연언어란 “인간의 언어”를 의미하며 (반대말은 인공 언어로 Python, C언어 등이 대표적인 사례), 자연언어처리는 이러한 인간의 언어를 컴퓨터가 처리하는 것을 의미합니다. 형태소분석, 구문분석, 의미분석, 화용분석 등의 근간 연구를 거쳐, 기계번역, 문서요약, 질의응답, 대화 시스템 등 다양한 응용 연구들이 발산되었다가, 현재는 많은 자연언어처리 하위 분야들이 초거대 언어모델 (Large Language Model, LLM)로 수렴되는 현상을 보이고 있습니다.
모두를 위한 “언어모델의 역사”
컴퓨터는 극단적으로 표현하면 0과 1 밖에 이해하지 못합니다. 즉 인간이 사용하는 언어를 직접적으로 이해할 수가 없다는 것이죠. 그렇다면 컴퓨터에게 인간의 언어를 이해시키려면 어떻게 해야할까요? 바로 인간의 지식 표현 체계, 즉 언어표현 체계를 컴퓨터가 이해할 수 있는 지식 표현 체계로 변경해주는 과정이 필요합니다. 이러한 역할을 하는 것이 바로 언어모델 입니다. 언어모델의 발전은 “어떻게 하면 인간의 언어를, 컴퓨터가 이해할 수 있는 지식 표현 체계로 잘 표현할 수 있을까?”라는 물음을 근간으로 발전되어 왔습니다. 조금 더 쉽게 표현하면 Characters (Human)를 어떻게 Numbers (Neural Network)로 잘 표현할 수 있을까에 대해 학자들의 고민이 계속됐던 것이죠. 이러한 질문에 대한 끝판왕적 답변이 바로 Large Language Model의 시대로 돌입하지 않았나 생각합니다.
이러한 물음을 근간으로 기술적 발전을 살펴보면, Traditional approach, 전통적인 방식의 단어 표현 (word representation) 방법은 원-핫 인코딩 (one-hot (or one-of-N) encoding) 방식을 주로 사용해왔습니다. 원-핫 인코딩은 내가 표현 하고 싶은 단어에만 1을 표시하고, 다른 단어에는 0을 표시하는 언어 표현 방식입니다. 이를 위해 단어집 (단어 집합 (Vocabulary))이 필요하며, 단어집에 존재하는 단어의 개수가 자연스레 벡터의 차원이 되는 것이죠. 만약 단어집에 Dog, Cat이라는 2개의 단어만 존재한다고 했을 때, 원-핫 인코딩 방식으로 Dog와 Cat을 표현하면 2차원의 벡터가 먼저 구성되게 되고, Dog는 {1,0}, Cat은 {0,1}로 표현되는 것입니다.

원-핫 인코딩 기반 단어 표현 체계 (출처: https://deep-eye.tistory.com/67)
그러나 원-핫 인코딩은 단어들간의 관계성을 고려하여 단어를 표현하지 못하며, 단어 집합의 크기와 벡터의 차원이 동일하게 되므로, 매우 높은 차원을 가져서 memory expensive하다는 문제점이 존재합니다.
Word2Vec
이러한 문제점을 해결하기 위하여, 의미정보가 가미된 지식 표현 체계가 등장하기 시작했습니다. 그 시작은 2003년에 밴지오 교수님에 의해 발표된 “A Neural Probabilistic Language Model”이라는 논문이며, 10년 뒤 “Efficient Estimation of Word Representations in Vector Space”라는 논문으로 발표된 Word2Vec이 가장 대표적인 사례입니다. “단어를 dense한 실수 벡터 공간에 매핑하되, 단어의 의미가 반영되도록 해보자”라는 목표를 가지고 진행된 연구들이며, 유사한 의미의 단어는 벡터 공간 상의 가까운 거리 내에 분포하도록 학습시키는 패러다임 입니다. 이러한 패러다임을 기반으로 Glove, FastText 등 다양한 연구들이 이루어졌습니다.
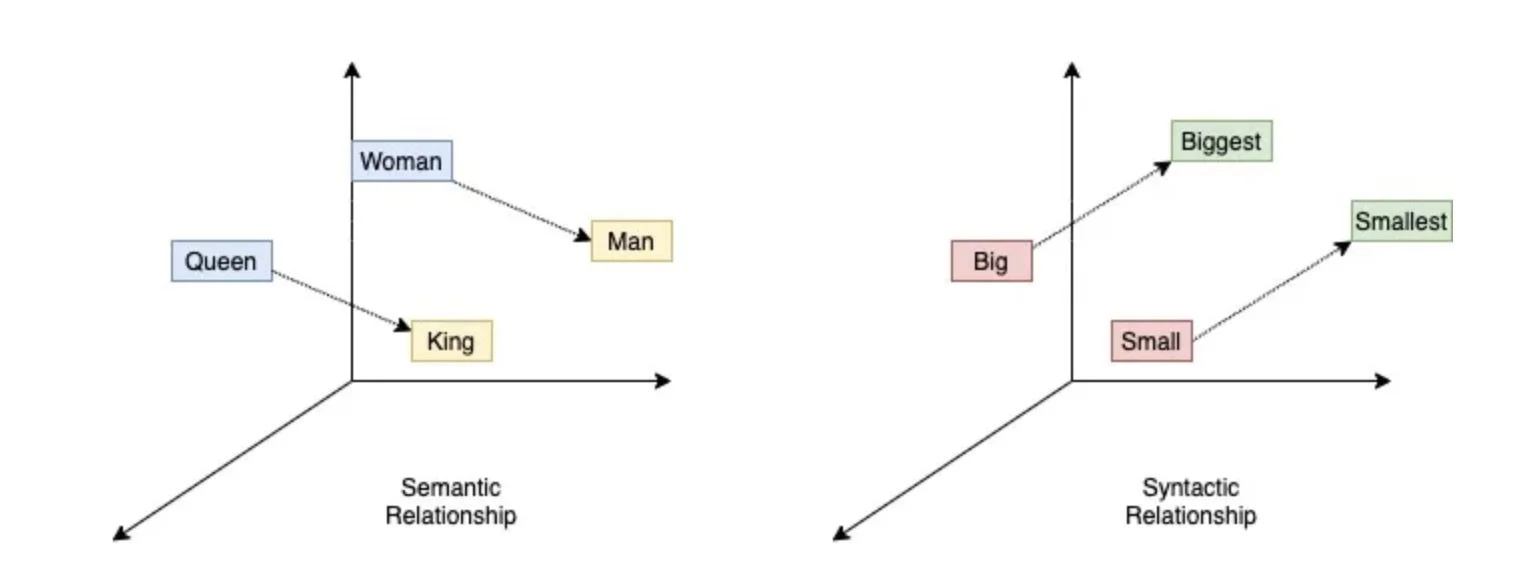
Word2Vec기반 단어 표현 체계 시각화 (출처: https://towardsdatascience.com/word2vec-research-paper-explained-205cb7eecc30)
그러나 해당 방식도 한계점이 존재했습니다. 바로 문맥 정보를 이해하지 못한다는 것이죠. 예를 들어 “사과 먹고싶다”와 “내가 정말 미안해, 사과할게”라는 2개의 문장이 있다고 해봅시다. 이를 컴퓨터가 이해할 수 있는 지식표현 체계로 표현하기 위해 고차원의 벡터로 변환을 해야하죠. Word2Vec 기반으로 해당 문장들을 표현하려다 보니, 2개의 “사과”가 같은 벡터로 표현되는 것을 발견하게 되었습니다. 이게 왜 문제일까요? “사과 먹고싶다”의 사과는 우리가 흔히 아는 과일 사과를 의미하며, “내가 정말 미안해, 사과할게”의 사과는 미안하다라는 뜻을 지닌 사과를 의미합니다. 즉 같은 단어이지만 뜻이 다른 것이죠.
따라서 문맥을 이해하고, 동음이의어는 다른 고차원의 벡터로 표현을 해주어야 합니다. 그렇게 하면 의미를 넘어 문맥을 고려한 언어 지식표현 체계가 가능하고, 더 좋은 자연어처리 모델들을 만들어낼 수 있는 것이죠. 이에 본격적으로 “문맥정보가 가미된 지식표현 체계”의 연구들이 등장하기 시작했으며, 그 시작은 바로 ”Deep contextualized word representations”이라는 논문으로 소개된 ELMo(Embeddings from Language Models) 입니다.
ELMo
ELMo는 크게 2가지의 패러디임을 불러왔습니다. 첫번째는 사전학습, 두번째는 양방향 학습입니다. ELMo는 사전 훈련된 언어 모델(Pre-trained language model)을 기반으로, 내가 원하는 특정 테스크로 Fine Tuning하는 기법을 본격적으로 적용한 연구입니다. 이는 자연언어처리를 하시는 분들이라면 너무나도 익숙할 Pretrain-Finetuning Approach인 것이죠. 형태소 분석, 구문분석, 문서요약, 기계번역 등 다양한 자연언어처리 하위 분야는 언어를 다룹니다. 즉 문맥정보가 가미된 잘 다듬어진 언어모델이 존재하고, 이를 잘 활용한다면 자연스레 자연언어처리의 다양한 하위 분야는 성능이 높아지겠죠. 즉 Pretrain을 통해 컴퓨터가 이해할 수 있는 문맥을 고려한 지식표현 체계를 잘 학습하고, 이를 내가 사용할 특정 task에 데이터로 미세조정을 해준다면, 자연스레 모델의 성능이 높아지는 패러다임으로 이해하시면 됩니다.

Pretraining-Finetuning 기반 언어모델 학습 패러다임 프로세스 (출처: https://www.ruder.io/state-of-transfer-learning-in-nlp/)
두 번째로 양방향 학습, biLM(Bidirectional Language Model)은 문맥을 이해하기 위해 문장의 앞에서 뒤로 (Forward), 그리고 뒤에서 앞으로 (Backward) 학습을 같이 진행하는 것입니다. 이는 순방향 언어모델과, 역방향 언어모델을 동시에 학습시키고, 출력값을 연결해주어 언어를 더 매끄럽게 표현할 수 있습니다.

Alammar, J (2018). A step in the pre-training process of ELMo [Blog post]. Retrieved from http://jalammar.github.io/illustrated-bert/
그러나 ELMo는 단순히 순방향과 역방향 언어모델을 합친 것이기에 진정한 “양방향 언어모델”은 아니었으며, LSTM기반으로 이루어져 있기에 여러 한계점 들을 내포하고 있었습니다.
Transformer기반 언어모델의 등장
ELMo 이후, Transformer기반 언어모델의 시대가 등장하게 됩니다. 대표적으로 OpenAI의 GPT, Google의 BERT입니다. GPT는 Transformer Decoder를 기반으로 하고 있으며, BERT는 Transformer Encoder를 기반으로 하고 있습니다. 자연언어처리는 자연언어이해와 자연언어생성으로 나눌 수 있는데, Encoder는 이해, Decoder는 생성에 해당한다고 생각하시면 됩니다.
언어를 표현하는 관점에서 BERT는 입력 문장에서 임의로 토큰을 마스킹 처리하고 그 토큰이 무엇인지 예측하는 방식으로 학습을 진행하는 Masked Language Model(MLM) 방식으로 학습을 진행하게 됩니다.
학습 데이터의 경우, 전체 데이터 중 15%에 대하여 단순 마스킹을 진행하면 되기에 별도의 레이블링 작업이 필요 없으며, 이는 방대한 데이터로 사전 훈련을 진행할 수 있음을 의미하죠. 그렇기에 대용량의 데이터로 사전학습을 진행할 수 있음과 동시에, MLM을 통해 진정한 양방향 기반 학습을 진행해 모델이 좋은 언어표현 체계를 습득할 수 있게 되었습니다. ELMo는 단방향 모델 2개를 결합하여 양방향 의존성 문제를 해결했던 것과 달리, BERT는 단일 모델로 양방향 의존성을 모두 학습한, 진정한 양방향적 모델인 것이죠.
GPT의 경우 이전 단어열을 기반으로 다음 단어가 무엇인지 예측하는 방식으로 학습을 진행하여 언어를 표현하였기에 자연언어생성기반 언어모델이라고 생각하시면 이해하기 쉽습니다. 이러한 GPT의 모델의 크기와 학습 데이터를 점점 키워가게 되어 GPT2, GPT3를 지금의 GPT4까지 등장하게 된 것이죠.

Transformer 이후 GPT 계열의 발전 계보도 (출처: ChatGPT: Jack of all trades, master of none)
BERT와 GPT의 양강 구도 이후, 많은 연구들이 발산되는 시기가 등장하게 됩니다. 크게 2가지 방향성이 있는데요. 첫번째는 “모델의 크기를 키우자!라는 방향성”, 2번째는 “모델의 크기를 키우기 보다 약점을 보완하거나, 서비스 가능한 수준으로 모델을 경량화 하자!”라는 방향성입니다. 첫번째 방향성의 결실이 바로 ChatGPT, GPT-4, HyperClova 등의 모델이며, 이로 인해 현재 Large Language Model(LLM)의 시대로 접어들게 되었습니다.
두 번째 방향성의 대표적인 모델로는 ALBERT, Linformer, Performer 등과 더불어 Quantization, Distillation, Pruning 등의 연구들이 이루어졌습니다. 또한 언어모델이 인간의 기본적인 상식 정보를 모르는(ex. 한국에서 미국을 어떻게 갈 수 있냐고 물으면 걸어서 갈 수 있다고 답변하는 등) 부분이 많다는 지적과 동시에 심볼릭 기반 지식정보를 뉴럴넷에 같이 학습을 시키려는 neural symbolic한 연구들이 많이 이뤄지기도 했습니다. 이러한 2가지 방향성은 LLM의 시대에도 유사한 현상을 보이고 있습니다.

Transformer 기반 언어모델 대항해 시대의 등장, Transformers Family Tree (출처: Transformer models: an introduction and catalog)
LLM 시대의 필수 요소
지금은 LLM의 시대입니다. 먼저 LLM을 만들기 위해서 필요한 4대 요소는 다음과 같습니다. 첫째로는 ‘인프라’입니다. 초거대규모의 클라우드와, 슈퍼 컴퓨팅, 데이터 센터 등이 필요합니다. 즉 LLM을 위한 하드웨어와 이를 뒷받침할 운영환경이 필요하죠. 이는 AI+클라우드를 중심으로 비즈니스 패러다임이 이동할 것을 시사합니다.
두 번째는 ‘BackBone Model’입니다. ChatGPT도 결국 GPT 3.5를 기반으로 학습을 진행하였고, 이후 공개될 HyperClova X 및 SearchGPT도 HyperClova 기반으로 학습을 진행한다고 합니다.
세번째로는 Tuning 기술입니다. 즉 비용 효율화를 위한 다양한 튜닝 기술을 필요로 하게 됩니다. “어떻게 경량화 할 것인가?”에 대한 큰 물음을 기반으로 행렬 연산 최적화를 위한 반도체 기술이 상당히 중요합니다. 네이버도 최근 삼성전자와 MOU를 맺으며 반도체 기술의 중요성을 인지하고 다양한 연구를 펼치고 있으며, NVIDIA의 주가도 급상승 한것이 반도체 연구의 필요성을 나타내는 반증이기도 합니다.
마지막으로는 고품질 및 다량의 학습 데이터가 중요합니다. Instruction 데이터, Human Feedback 데이터 뿐만 아니라, backbone 모델을 학습 시키기 위한 대용량 데이터가 필요로 하게 됩니다.
이렇게 4가지 요소를 기반으로 다양한 기업에서 LLM을 만들기 위한 각축전을 펼치고 있으며, 모델과 데이터가 많아지니 언어를 표현하는 지식 표현체계가 상상 이상으로 좋아지고, 이를 기반으로 모델의 다양한 능력들이 창발되고 있는 시대입니다.
결론적으로 언어 모델(Language Model, LM)은 “언어”를 컴퓨터가 이해할 수 있는 체계로 “모델링” 하는 것입니다. 이러한 모델링의 관점에서 원-핫 인코딩부터 지금의 GPT4까지 쭉 발전되어 왔다라고 이해하면 전반적인 자연언어처리기반 언어모델의 역사를 이해하시는데 도움이 되리라 생각합니다.
데이터 관점에서 사람에 대한 정의
지금까지 첫번째 섹션을 통해 자연언어처리의 정의를 살펴보았고, 두 번째 섹션에서는 언어모델 기반 자연언어처리의 흐름을 살펴보았습니다. 이제 본격적으로 Data-Centric AI 관점에서 자연언어처리 역사를 살펴보겠습니다.
과거부터 현재까지 인공지능의 역사를 사람과 데이터의 관계적 관점을 바탕으로 재해석하기에 앞서, 사람과 데이터는 규칙 기반 시대부터 LLM 시대까지 떼려야 뗄 수 없는 관계였다는 점을 먼저 말씀드리고 싶습니다.
데이터 관점에서 사람에 대한 정의는 크게 2가지로 나눌 수 있다고 생각합니다. 첫 번째로는 “전문가”라는 사람, 두번째로는 “대중” 입니다. 여기에는 누구나 포함될 수 있습니다. 사람에 대한 이 두 가지의 정의가 인공지능 데이터의 역사를 이끌어 왔습니다.
규칙기반 자연언어처리: “전문가”의 시대
규칙기반 시대는 “전문가”라는 사람의 시대였습니다. 이 당시에는 언어학자의 역할이 중요 했습니다. 형태소 분석, 구문분석, WordNet 등은 언어학 전문가만 만들 수 있었던 시대입니다. 언어학적 지식을 기반으로 데이터를 표상해야하기에, 전문성이 굉장히 중요했던 시대이죠.

규칙기반 자연언어처리 Task 예시 (출처: https://hyowong.tistory.com/entry/자연어처리-프로세스)
통계기반 자연언어처리~기계학습 및 딥러닝의 시대: “대중”의 시대
반면 통계기반 자연언어처리 및 기계학습 및 딥러닝의 시대는 데이터 관점에서 “대중”의 시대였습니다. 즉 우리의 역할이 굉장히 큰 시대였지요. GPU, 알고리즘(오픈소스), 빅데이터의 3박자가 딥러닝을 가속화 시킨 것은 다들 아실거라 생각합니다. 이 중 사실 빅데이터는, 결국 우리가 만들어준 데이터입니다. Wikipedia, 네이버 블로그, 카페, 지식인 등 수많은 웹페이지에 존재하는 텍스트들, 결국 우리 모두가 데이터를 무의식적으로 생성하고 있던 것입니다. 이러한 대규모 데이터를 바탕으로 통계기반 방법론들이 주류를 이루다가 딥러닝으로 넘어오게 된 것이지요.

“웹에서 데이터를 무의식적으로 생성한 우리들”
Pretrain-Finetuning의 시대: “대중” + “전문가”의 시대
딥러닝 시대의 중반 쯤 Pretrain-Finetuning 기법이 유행했습니다. 이 시대는 전문가와 대중이 공존한 시대였습니다. Pretrain은 말그대로 사전학습입니다. 사전학습을 할 때에는 대중이 만든 wikipedia와 같은 large corpus를 기반으로 학습을 진행합니다. 그 pretrain model을 기반으로 형태소 분석도 하고, 구문 분석도 하고, 문서 요약도 하는 등 사용자가 원하는 특정 task로 미세조정을 진행하죠. 이 미세조정을 진행할 때에는 여전히 전문가가 만든 데이터들로 튜닝을 진행합니다.
Pretrain-Finetuning 기법의 등장으로, 자연스레 데이터의 역할은 여러 Task를 객관적으로 동시에 평가할 수 있는 체계가 필요해졌습니다. 그것이 바로 여러분이 잘 아시는 벤치마크 데이터 입니다. 이 시대에 한국에서 대표적인 KLUE, 미국에서 만든 GLUE, SuperGLUE, SQUAD 등 벤치마크 데이터가 등장하기 시작했죠. 즉 평가를 잘할 수 있는 데이터의 시대가 도래하면서 전문가와 대중이 모두 기여를 하게 된 시기라고 볼 수 있습니다. 앞서 말씀드린 두 가지 유형의 사람이 공존한 시대였죠.

KLUE 밴치마크 (출처: https://klue-benchmark.com/)
뉴럴심볼릭의 시대: “전문가”의 시대
중간에 뉴럴 심볼릭이라는 패러다임도 등장했습니다. 딥러닝 모델의 명확한 한계들을 살펴보면 상식정보가 부족하고 추론력이 떨어지며, explainable하지 않다는 것입니다. 위에서 예를 들었던 것과 같이 한국에서 뉴욕은 걸어서는 못가고, 항공이나 배로 갈 수 있다. 맨하튼은 뉴욕 안에 있다 등과 같은 상식정보가 딥러닝 모델에게 부족했습니다. 이 상식정보들을 Knowledge graph 형태로 구축하고, 이를 딥러닝 모델에 injection 시키는 것이 뉴럴심볼릭입니다. 이러한 데이터는 사실 완전히 전문가의 영역이죠. 아래 예시를 보시면 모나리자는 다빈치가 그렸으며, 현재 루브르 박물관에 있고와 같은 상식 정보를 그래프 데이터로 구축하는 형태입니다.

Knowledge Graph의 예시 (출처: https://www.komunicando.es/que-es-el-knowledge-graph/)
Large Language Model의 시대 Part 01 - “대중”의 “무의식적” 데이터 생성의 시대
이후, 빅데이터와 함께 엄청난 모델의 크기로 학습한 LLM의 시대가 등장했습니다. 여러분이 잘 아시는 GPT3, HyperClova 등이 대표적인 예시이죠. 모델과 데이터를 키웠더니 상상 이상으로 다양한 일들을 처리하는 Big Model의 시대가 시작된 것이죠. 기존 Pretrain-Finetuning 기법과 다르게 모델의 파인튜닝 없이 하나의 모델로 다양한 task를 처리할 수 있는 시대가 온 것입니다.
데이터의 관점으로 이 시대는 어떻게 정의할 수 있을까요? 대표적인 예시인 Hyper Clova의 학습 데이터를 살펴보면 네이버 블로그, 네이버 카페, 네이버 뉴스, 네이버 지식인 등의 데이터입니다. 즉 LLM의 시대도 결국 우리가 만든 초거대 데이터로 학습을 진행하였습니다. 즉 우리는 계속 무의식적으로 인공지능 학습 데이터를 생성하고 있었던 것이죠.

HyperClova 학습 데이터 정보 (출처: NAVER AI NOW)
Large Language Model의 시대 Part 02 - “대중”의 “의식적” 데이터 생성의 시대
LLM의 시대에서 가장 혁신적인 제품은, 여러분들이 다 아시는 ‘ChatGPT’일 거라 생각합니다. ChatGPT 시대의 핵심은 Human Feed back Data 입니다. 여기서의 Human은 꼭 전문가가 아닙니다. 우리 모두입니다.
그러나 LLM시대는 제가 무의식적 데이터 를 생성을 했던 우리의 시대라고 말씀드렸습니다. 그러나 ChatGPT는 이와 조금 다르게, 우리가 직접 피드백을 주며 “의식적 데이터”를 생성하는 시대가 왔습니다. 즉 데이터 maker는 이제 전문가의 영역만이 아닙니다. 우리 모두 인공지능 모델 개발에 참여할 수 있게 된 것이죠. 즉 지금은 “모두를 위한 데이터의 시대”다. 우리 라는 사람이 의식적으로 직접 피드백을 준 데이터로 학습을 하다보니, ChatGPT는 사람이 쓴 것과 같은 글을 생성해내는 것이죠.
지금까지 말씀드린 History of AI는 전적으로 데이터의 관점에서 말씀을 드려보았습니다. 꼭 말씀드리고 싶은 것은 “규칙기반 시대부터 사람과 데이터는 필수불가결한 관계였고”, 앞으로도 데이터에 있어서 사람의 역할이 더더욱 중요해질 것이라는 점 입니다.
마무리하며
ChatGPT와 같은 LLM이 왜 이렇게 뜨거운 감자일까요? 저의 개인적인 생각으로는 연구적 임팩트와 세상의 임팩트(패러다임의 전환)가 같이 온 유일한 사례가 아닐까 생각합니다. 연구적 임팩트란 정말 기술적으로 페러다임이 전환된 즉 turn over 된 것을 의미하고, 세상의 임팩트는 우리 세상 사람 모두가 체감하는 그런 사건을 의미합니다.
딥러닝의 등장 이후 자연언어처리 분야에서 가장 큰 연구적 임펙트는 “Word2Vec”, “Transformer (Attention)”, “Reinforcement Learning from Human Feedback (RLHF)”라고 생각합니다. Word2Vec은 언어의 지식 표현 체계를 turn over 했습니다. one-hot encoding 즉 단어간의 관계를 전혀 알 수 없었던 지식 표현 체계를 단어간의 관계를 이해할 수 있는 의미기반 지식 표현 체계로 뒤바꾼 기술이죠. Transformer는 Attention으로만 CNN과 RNN의 기술을 turn over 해버렸고, RLHF는 기존 MLE, 즉 확률 기반 생성 방식에서 강화학습 기반 생성방식으로 패러다임을 전환했습니다. 이 RLHF가 ChatGPT에 적용된 기술입니다.
그 다음 세상의 임펙트를 살펴볼까요? 제가 생각할 때 3개를 뽑아보자면 IBM Watson, AlphaGo, ChatGPT 입니다. IBM Watson은 인공지능이 최초로 퀴즈쇼에 나가서 이긴 사례이고, 알파고는 이세돌 9단과의 대국에서 승리한 인공지능 프로그램으로 많은 분들이 알고 계실 겁니다. ChatGPT는 월간 사용자가 1억 명을 넘었습니다. 즉 이렇게 연구적 임팩트와 세상의 임팩트가 같이 온 거의 유일한 사례이기에, 그 어느 때보다 ChatGPT의 반응이 뜨겁지 않나라고 저는 생각합니다.
ChatGPT의 핵심은 Human feed back data, 즉 양질의 데이터입니다. 앞으로 인공지능 기업의 핵심 역량은 결국 양질의 데이터를 확보했느냐 안했는냐로 갈리게 될 것이라고 생각합니다. 기업에서 AI 비즈니스를 할 때에도 데이터를 잘 확보할 수 있는 구조인지, 더 나아가서 양질의 데이터를 만들어 낼 수 있는 프로세스가 갖춰져 있는지를 고민해야할 것 입니다.
ChatGPT에 힘입어 앞으로 다양한 수익 모델이 새롭게 등장할 것이라고 생각합니다. 그 중심엔 바로 구독형 인공지능 비즈니스 모델이 떠오르게 될 것이라 생각합니다. 여기서 중요한 점은 저는 데이터를 구독하는 시대 보다는 모델을 구독하는 시대가 찾아올 것이라 생각합니다. 데이터를 공유하기에는 기업의 부담이 클 것입니다. 좋은 데이터는 곧 기업의 경쟁력이기 때문이고 개인정보 이슈와 같은 다양한 policy를 고려해야 되기 때문이죠. 그렇기에 좋은 데이터를 만들고 이를 모델로 만들어 공유하는 시대, 즉 AIaaS(AI as a Service)의 시대로 접어들게 될 것으로 예상합니다. 광고의 패러다임도 바뀔 것입니다. 직접광고, 간접광고를 넘어서, 이제는 생성 광고를 통해 돈을 버는 시대가 될 수도 있는 시대가 올 것으로 예측해 볼 수도 있겠습니다.
결국 기업의 Data팀 확보는 곧 경쟁력이 될 것 입니다. 더불어 모델과 데이터 모두 잘할 뿐만 아니라 2개의 균형성과 조화를 이룬 기업이 앞으로 살아남게 될 것 입니다. 새로운 수익 모델의 등장, 명확해진 방향성 등장, 새로운 직군의 등장 등 결국 Data가 AI 시대의 중심이 될 것 입니다. Code in SW out의 패러다임이었던 SW 1.0을 지나 Data in SW out의 SW 2.0의 시대가 도래한 것 처럼 말입니다. 본 기고글이 많은 분들께 도움이 되기를 바라며 이 글의 핵심인 DATA! DATA! DATA!를 적으며 마무리 해보겠습니다.
-
-
2020년 10월 설립한 업스테이지는 이미지에서 원하는 정보를 추출해 이용할 수 있는 OCR기술을 비롯, 고객 정보와 제품 및 서비스 특징을 고려한 추천 기술, 의미기반 검색을 가능케하는 자연어처리 검색기술 등 최신 AI 기술을 다양한 업종에 맞춤형으로 손쉽게 적용할 수 있는 노코드-로코드 솔루션 ‘Upstage AI Pack’을 출시, 고객사들의 AI 혁신을 돕고 있다. Upstage AI Pack을 이용하면 데이터 가공, AI 모델링, 지표 관리를 쉽게 활용할 수 있을 뿐 아니라 지속적인 업데이트를 지원, 상시 최신화 된 AI 기술을 편리하게 사용할 수 있다. 더불어, AI 비즈니스 경험을 녹여낸 실습 위주의 교육과 탄탄한 AI 기초 교육을 통해 AI 비즈니스에 즉각 투입될 수 있는 차별화된 전문 인재를 육성하는 교육콘텐츠 사업에도 적극 나서고 있다.
업스테이지는 구글, 애플, 아마존, 엔비디아, 메타, 네이버 등 글로벌 빅테크 출신의 멤버를 중심으로 NeurlPS를 비롯, ICLR, CVPR, ECCV, WWW, CHI, WSDM 등 세계적 권위의 AI 학회에 다수의 우수 논문을 발표하고, 온라인 AI 경진대회 캐글(Kaggle)에서 국내 기업 중 유일하게 두 자릿수 금메달을 획득하는 등 독보적인 AI 기술 리더십을 다지고 있다. 업스테이지 김성훈 대표는 홍콩과학기술대학교 교수로 재직하면서 소프트웨어공학과 머신러닝을 융합한 버그 예측, 소스코드 자동생성 등의 연구로 최고의 논문상인 ACM Sigsoft Distinguished Paper Award 4회 수상, International Conference on Software Maintenance에서 10년 동안 가장 영향력 있는 논문상을 받은 세계적인 AI 구루로 꼽히며, 총 700만뷰 이상을 기록한 ‘모두를 위한 딥러닝’ 강사로도 널리 알려져 있다. 또한, 업스테이지의 공동창업자로는 네이버 Visual AI / OCR 을 리드하며 세계적인 성과를 냈던 이활석 CTO와 세계 최고의 번역기 파파고의 모델팀을 리드했던 박은정 CSO가 참여하고 있다.